当信息抽取成为对于大语言模型的生成式查询?
浅谈大模型场景下的信息抽取范式及未来
信息抽取旨在从海量的非结构化信息中抽取结构化信息。信息抽取不仅是为了方便信息的提取和利用,帮助人们更好的理解信息中的重点,更是知识编码、计算机理解和整理自然语言及知识图谱构建的重要部分。近年来,由于传统信息抽取方法的独立性和信息抽取任务本身的多样性、复杂性、需求特定和数据稀缺等问题,如何将各类信息抽取任务进行整合,使用生成式的方法统一地完成各类任务成为研究重点。由于生成式预训练大模型的效果日益强大,许多方法使用生成式模型统一进行信息抽取任务,信息抽取范式从传统的级联抽取逐渐向大模型生成式抽取的方向转变。信息抽取领域上呈现出趋向于生成范式的转移。
在本篇报告中,我首先在‘基础任务介绍’这一节中详细讲解信息抽取的任务定义及其难点、传统信息抽取方法的局限性,及基于改进传统方法局限的动机,通用信息抽取任务和生成式方法的提出。
在 2021 年-2022 年,由于基础模型的指令遵循能力和生成能力尚且不足,主要采用预训练注入结构化信息生成能力+具体任务微调的方式来进行生成。在这方面,我主要介绍 UIE 和 USM 两个具有继承性的经典工作。但是微调方法具有泛化性不足,灾难性遗忘的问题。在 2022 年之后,由于大模型的强大逐渐展露,有很多工作关注于将大模型应用于信息抽取中。在这方面,我介绍了 Code4Struct 和 Code IE 两个工作。然而,使用上下文方法进行信息抽取无法让模型很好的学到结构化信息生成和足够的标签信息,我介绍了一篇使用 Reranker 的文章,细致分析了该问题并提出了大小模型结合方法的改进。
我个人认为信息抽取的前沿发展可以针对于两个方向:构建领域的抽取大模型来解决泛化性和专业领域构建多个小模型,通过大模型组合调用多个小模型完成任务。由于微调和提示学习局限性,InstructIE 和 InstructUIE 提供了用于指令微调的数据集,将指令微调用于大模型中,在不需要对下游任务进行微调的同时取得了较好的效果。在工具学习方面,研究更加关注如何通过指令选择合适的工具和如何针对工具的性质和环境决定合适的行为。在这一节我综述了代表性的工作 PAL 和 CREATOR 等等。在信息抽取领域,工具学习主要用于模型使用搜索信息来辅助生成,暂时没有利用多个小模型来针对性完成复杂的任务的工作,但我相信不久后也能看到这样的未来。
最后,我介绍了个人在构建中文通用信息抽取大模型的一些探索。其中包括项目的整体架构、指令构建、模型选择和泛化实验分析等等。在未来,我相信知识工程会和大模型进行有机结合,通用的大模型会调度图谱和工具进行更高质量的信息理解和抽取,结构化的知识能够帮助大模型提高生成质量并在更多领域展开应用。
基础任务介绍
在大数据时代,无结构的文本数据占据了数据总量的大部分,如新闻、社交媒体、论坛等。这些数据包含了大量有价值的信息,但由于其格式的复杂性,我们往往无法直接使用。知识工程(Knowledge Engineering)是一种将专家的知识转化为计算机可以理解的知识库的技术,这个过程通常包括知识获取、知识表示、知识推理等几个步骤。通过知识工程,我们可以将大量的无结构数据转化为结构化的知识,供计算机进行深度分析和应用。
信息抽取(Information Extraction,IE),可以说是知识工程中知识获取的重要部分,是一种用于从生活中海量的无结构文本中提取珍贵信息的重要技术。这种技术不单单是一个单一的过程,而是包含了一系列的子任务,这些子任务各自拥有其独特的目标和方法。具体来说,这些子任务主要包括命名实体识别(Named Entity Recognition,NER)、关系抽取(Relation Extraction)以及事件抽取(Event Extraction)等。这些图谱构建的重要部分在老师的上课过程也花费了非常多的的时间进行讨论。
以乔布斯(Steve Jobs)为例,我们首先可以通过命名实体识别技术识别出这个名字代表一个具有特殊意义的实体,也就是苹果公司的联合创始人。然后,我们可以使用关系抽取技术从相关的文本中抽取出他与其他实体之间的关系,例如他是苹果公司的创始人,他与沃兹尼亚克(Steve Wozniak)是合作伙伴等。
至于事件抽取,其目标在于从文本中抽取出具有特定结构和语义的事件。比如,当我们读到"乔布斯在 1997 年成为了苹果公司的 CEO"这样的句子时,我们可以识别出触发词"成为",然后构建一个事件框架,这个框架中包含了事件的主体(乔布斯)、事件的动作(成为)以及事件的对象(苹果公司的 CEO)。此外,我们还可以抽取出事件发生的时间(1997 年)。通过这样的方法,我们可以把原本无结构的文本转化为有结构的事件,这些事件可以供计算机进一步理解和分析。
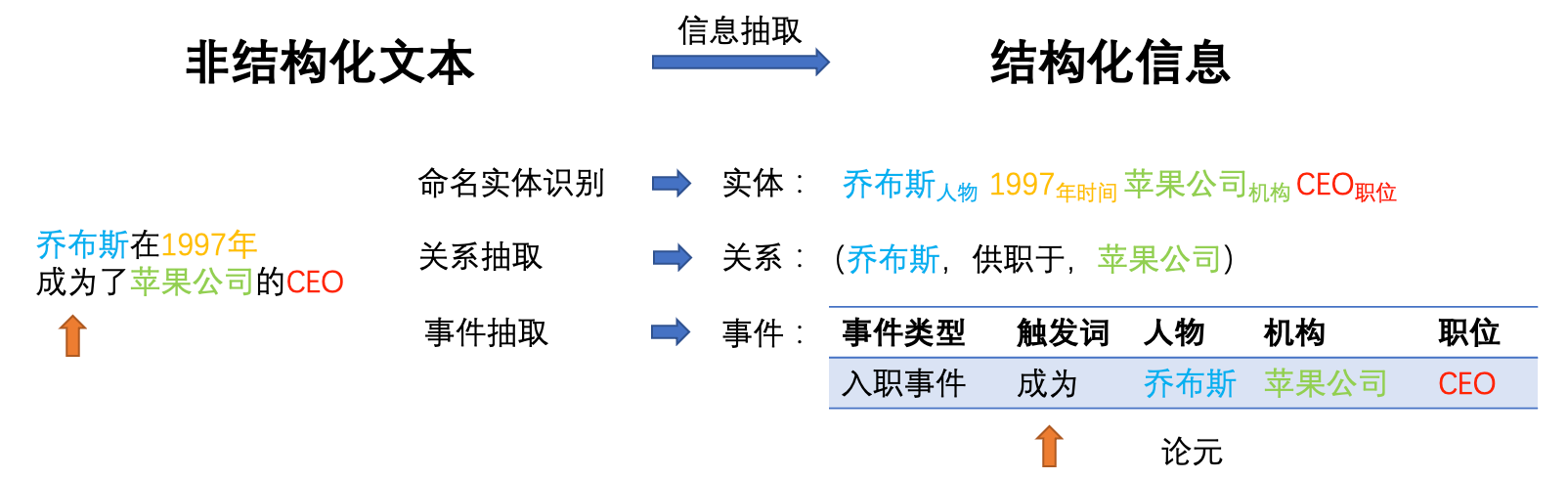
信息抽取是构建知识图谱的重要步骤,通过信息抽取,我们可以从大量的无结构文本中抽取出实体和它们之间的关系,从而构建出知识图谱。知识图谱(Knowledge Graph)是一种结构化的知识表示方法,通常以图的形式表示知识,其中节点表示实体,边表示实体之间的关系。
在信息抽取任务中,主要面临着四个主要的问题:
任务的多样性和结构复杂性构成了信息抽取的一大挑战。如您所述,我们有不同的抽取任务需求,这些任务有着不同的抽取内容要求,且结构复杂,例如实体、关系、事件等。每一种任务都需要特定的抽取技术,以满足任务的特定需求。
领域需求特定也是信息抽取面临的难题。不同领域的抽取要求不同,需要根据具体的领域,设计不同的模型和数据集。如医疗领域需要关注疾病、药物、治疗手段等信息,金融领域关注公司、管理人员、财务事件等信息,舆情领域关注国家、政党、选举等信息,而文化领域则可能关注诗词、语言、典故等信息。
数据标注难度也是一大问题。对于一个比较完整的样本,我们需要标注触发词、关系、论元等信息,这需要大量的人力和时间成本。尤其是在没有足够标注数据的情况下,训练一个高效的抽取模型会变得十分困难。当前方法大多依赖于大规模和细粒度的子任务标注,这使得抽取模型难以从科研中走向真正的实用。因为在实际应用中,我们往往难以获得大规模的细粒度标注数据,这会限制模型的性能和应用范围。
在 2022 年之前,主流的信息抽取建模方式通常采取“抽取范式”,这种范式主要分为两个步骤:
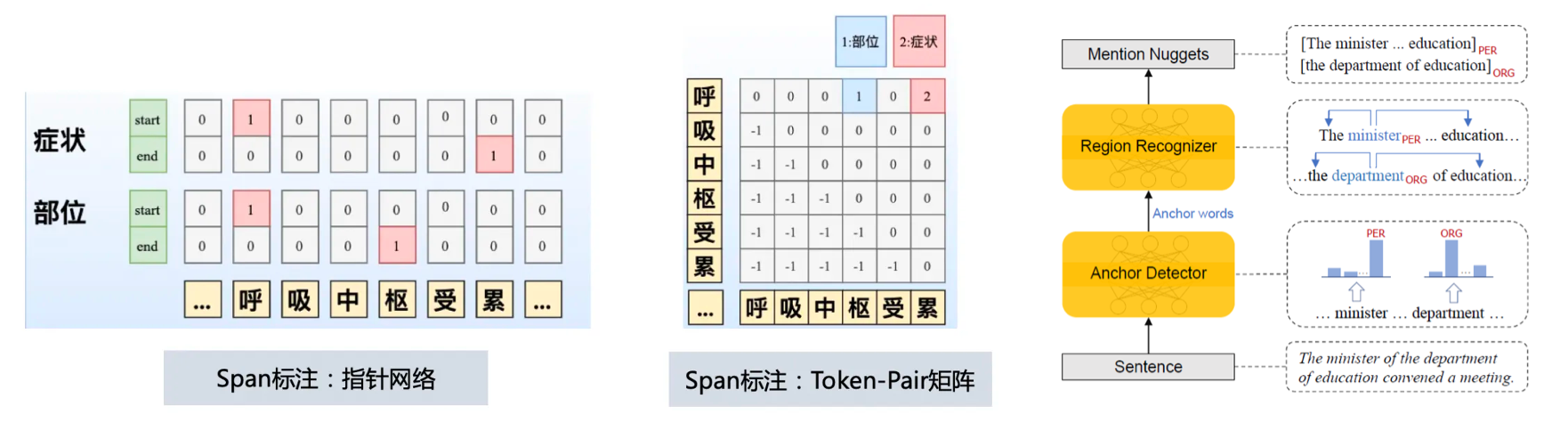
通过序列标注或者 span 标注,可以从句子中找出元组,即实体或事件的主要组成部分。这个过程通常涉及到词性标注、命名实体识别等技术,可以提取出实体、属性、关系以及事件等信息。
在进行了标记之后,我们可以开始建模 N 元 Span 之间的关系。这种模型通常被称为关系抽取模型,其主要目标在于识别出实体或事件之间的特定关系。通过这种模型,我们可以进一步解决复杂实体、关系、事件抽取问题。
事件抽取的过程可以采取“级联抽取”的方式,即先通过序列标注或span标注抽取出触发词span,然后再抽取出论元span。触发词span通常表示事件的动作或状态,而论元span则表示与事件相关的实体。通过这种方式,我们可以构建出一个完整的事件框架,这个框架包含了事件的动作、主体、对象以及其他相关信息。
通过这个过程,我们可以从原始的无结构文本中抽取出结构化的关系和事件。这种信息抽取范式已经在多种应用中得到了广泛的使用,包括情感分析、知识图谱构建、语义搜索等。
确实,“抽取范式”的优点在于其在各个任务上都能达到较高的准确性,但同时也面临着一些挑战。
这种方法需要任务特定的架构,这就需要专业人员对不同的任务进行调优,这无疑增加了技术门槛和维护成本。
不同任务的信息抽取(IE)模型被单独训练,相互之间没有共享信息,这在一定程度上降低了效率。对于一个公司来说,可能需要管理成百上千个信息抽取模型,这既增加了管理的复杂性,也会消耗大量的资源。
面对不同领域的需求,需要设计特定的 schema 并构建训练资源,构建训练模型,这会带来极高的构建成本。在面对具有特定需求的领域,如医疗、金融等,可能需要大量的领域知识和大量的领域特定的标注数据,这无疑增加了信息抽取的难度和成本。
因此,虽然“抽取范式”在一定程度上提高了信息抽取的准确性,但是它的任务特定性、相互独立的模型和高昂的构建成本等问题也限制了其在实际应用中的广泛使用。
所以近年来,通过使用一个模型端到端的进行抽取任务一直是研究的重点。因此“生成式”的抽取范式应运而生。生成式预训练模型(PLMs)如 BERT、GPT、T5、BART 等,已经证明了它们在各种自然语言处理(NLP)任务上的有效性。这些模型基于大型语料库进行训练,获取了丰富的语义和语法知识,这些知识可用于众多 NLP 任务。这些 PLMs 的一个关键优势是它们的训练过程和任务无关,这使得 PLMs 能在无监督的方式下利用大量的未标注数据。然后,通过微调,即调整预训练模型的参数以适应特定任务,PLMs 可以被用于各种特定的 NLP 任务。并且在多任务学习环境中,预训练模型+微调的方法更显优势。由于所有的任务都共享预训练模型的参数,这种方法能促进任务间的知识转移,提高模型在各个任务上的性能。
因此,虽然“抽取范式”在一定程度上提高了信息抽取的准确性,但是它的任务特定性、相互独立的模型和高昂的构建成本等问题也限制了其在实际应用中的广泛使用。
所以近年来,通过使用一个模型端到端的进行抽取任务一直是研究的重点。因此“生成式”的抽取范式应运而生。生成式预训练模型(PLMs)如 BERT、GPT、T5、BART 等,已经证明了它们在各种自然语言处理(NLP)任务上的有效性。这些模型基于大型语料库进行训练,获取了丰富的语义和语法知识,这些知识可用于众多 NLP 任务。这些 PLMs 的一个关键优势是它们的训练过程和任务无关,这使得 PLMs 能在无监督的方式下利用大量的未标注数据。然后,通过微调,即调整预训练模型的参数以适应特定任务,PLMs 可以被用于各种特定的 NLP 任务。并且在多任务学习环境中,预训练模型+微调的方法更显优势。由于所有的任务都共享预训练模型的参数,这种方法能促进任务间的知识转移,提高模型在各个任务上的性能。
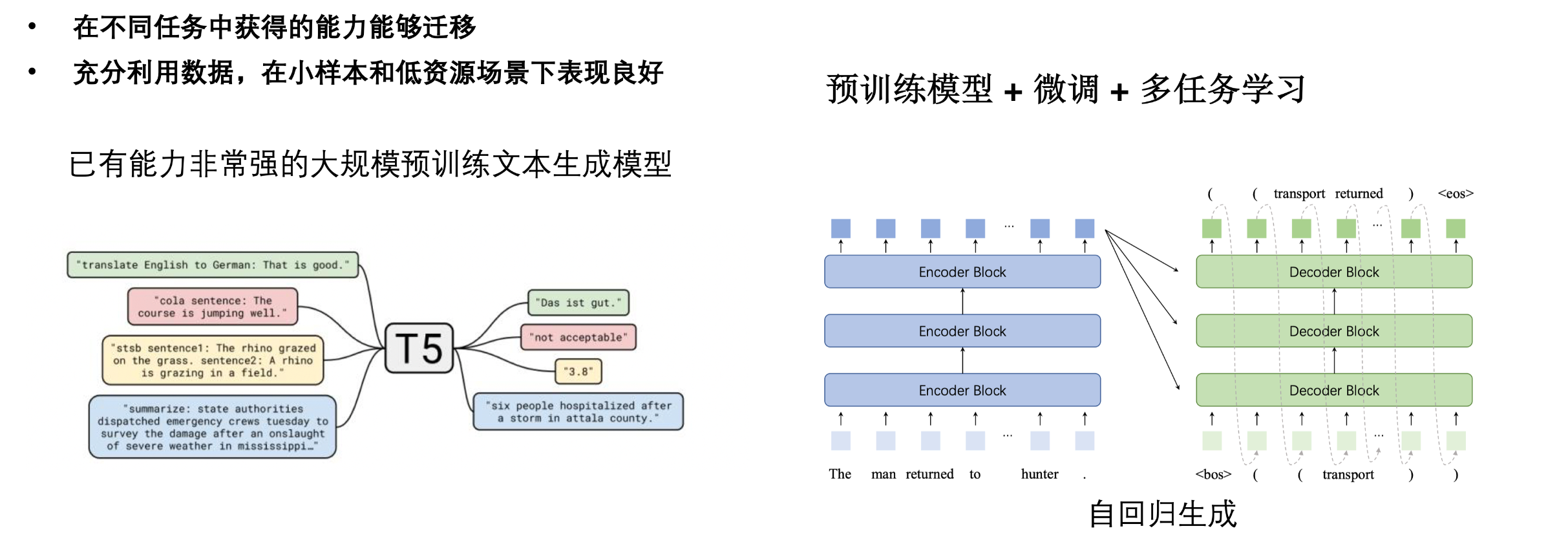
将输出从传统的翻译任务变为自回归的生成结构化文本,也是 PLMs 应用于信息抽取任务的关键一步。这种方式不需要特别的设置,也能够在低资源场景中产生不俗的结果。这是因为生成式预训练模型在训练过程中学习了大量的语言知识,这些知识可以帮助模型理解并生成具有特定结构的文本,从而实现信息抽取的目标。这种方法的好处在于,只需要调整生成式策略,就可以适配不同的抽取任务。因此,我们可以将信息抽取任务转化为带有语义理解的翻译任务。这种方式在一定程度上解决了传统方法中的问题,例如任务特定的架构、相互独立的模型以及高昂的构建成本。
设计这样的生成式框架时,我们有四个设计目标:一是通过生成式方法降低标注需求,利用大量无标注数据,获得更强的迁移学习能力和低资源环境的适应性;二是通过生成式模型,针对各种复杂的信息抽取任务实现统一建模,即端到端架构;三是设计文本的受限解码方式,以适应不同的信息抽取任务;四是研究适合的表示方法,以更好地表示和抽取文本中的信息 (Lu et al., 2021)。
这是让我非常具有兴趣是,在大模型还没有兴起的 2022 年,就已经发生了普遍性的范式转移转移。复旦大学邱锡鹏教授团对这一研究领域的最新进展和趋势进行总结 (Sun et al., 2022)。使用强大的预训练模型以生成式的方式完成各种各样的任务:需要的工程量更少,可解释性更强,同时也能更灵活地处理复杂的任务。通过结合自监督预训练,如 BART 和 T5,或者进一步以现有的语言模型对标注数据进行预训练作为初始化,这些范式可以实现与 (M) LM 相竞争的性能,甚至在某些情况下可能会更好。这无疑在暗示着一个事实:NLP 正在从领域化,逐渐走向通用模型的应用化。而在不久之后横空出世 chatGPT 及其席卷而起的大模型风潮,正式将生成式能否解决一切问题的探讨推上了高潮。
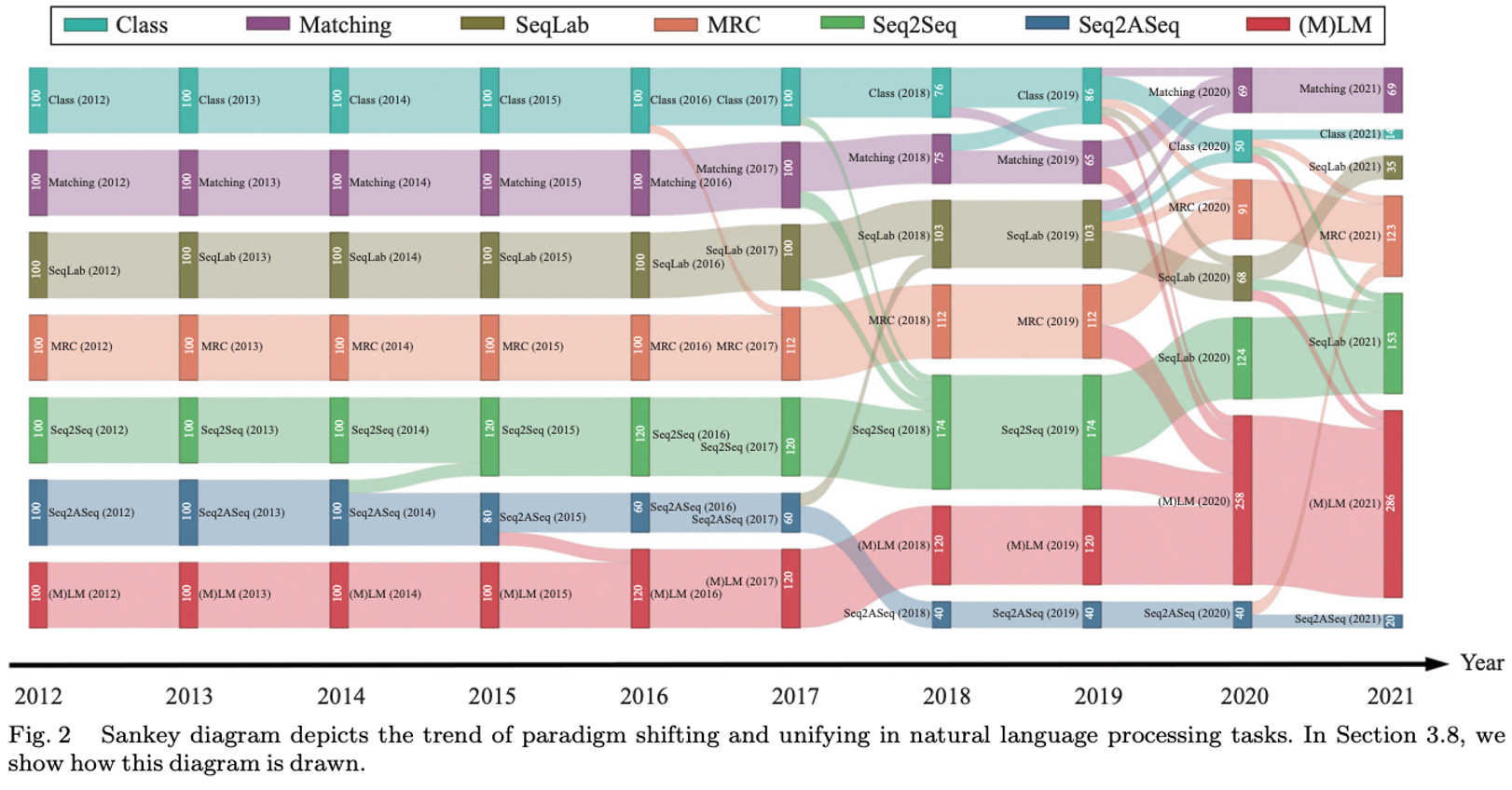
附我调研时总结的使用生成式方法解决信息抽取问题的几个代表性工作:
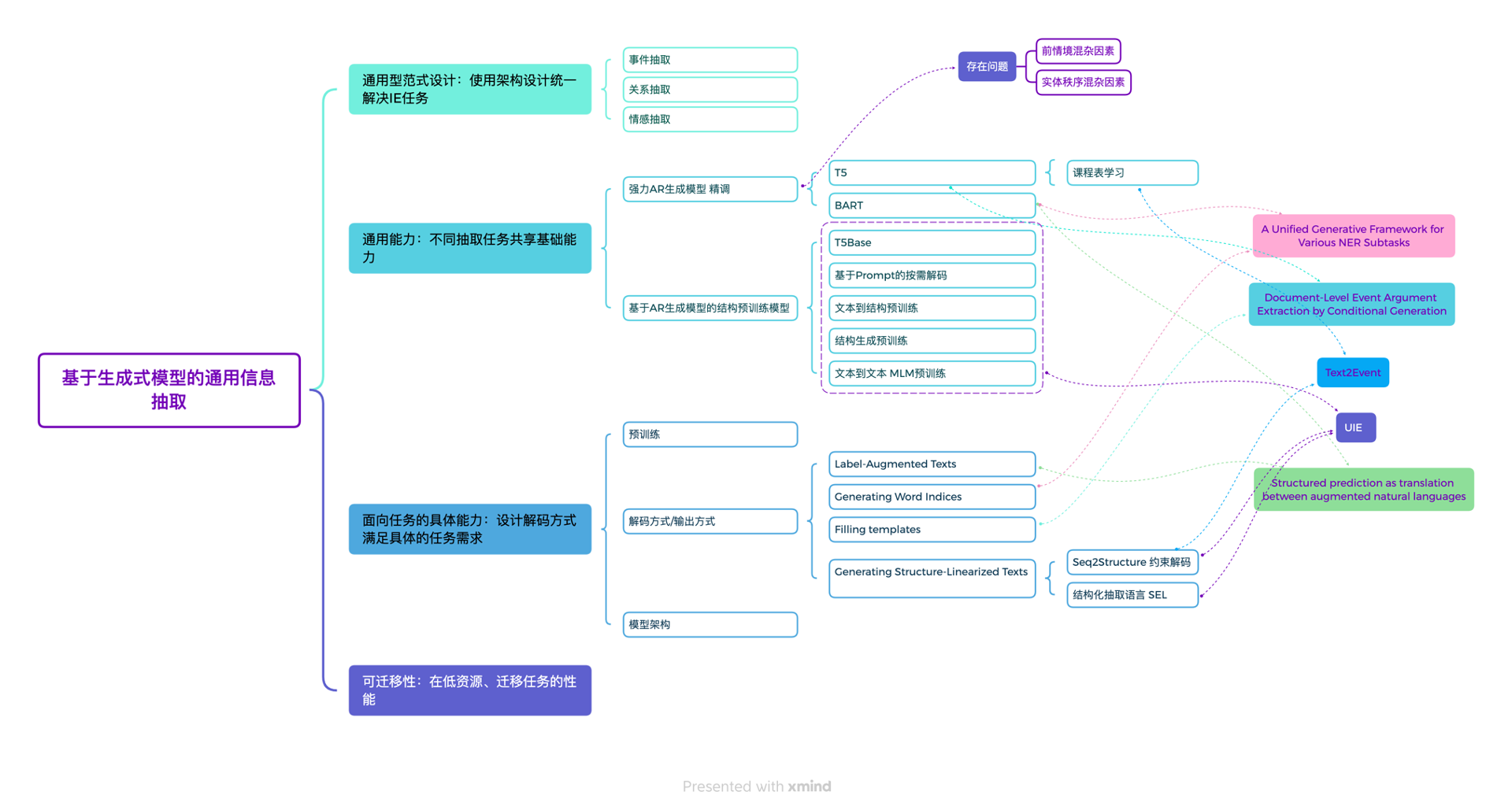
典型工作介绍
生成式的模型能够通过自定义结构体的生成方式,生成不同的结构体和相应的任务输出。在模型训练的过程中,可以输入各种任务文本,然后输出其对应的结构体,以实现自适应完成各种任务。这种使用方式的优点在于,多个任务可以共享一个底层架构,从而共享底层能力,提高效率。具体地说,这种使用方式可以分为以下几个阶段:首先,进行预训练任务,使其与下游任务相匹配。接着,根据下游需求,适当调整模型结构,考虑推理速度和抽取效率等因素。最后,根据具体下游任务的需求,采用符合任务需求的 Schema 解码方式,并通过正确的生成目标结构以及适当的表示和推理方式来完成任务。
首先,我会介绍基于提示学习+微调的方法。这种方法可以通过提示的方式来引导生成模型,从而达到更优秀的生成效果,在特定任务领域上进行微调可以最大程度地激发模型的性能。在介绍这种方法时,我会着重介绍典型的两个工作,即 UIE 和其改进版 USM。
UIE采用了提示微调的方法来进行多任务学习。通过设计三种任务,UIE获得了从文本到结构化体的能力。此外,为了建模不同任务,UIE通常会使用一种提示,但这种方式也存在缺点,缺少了各任务之间的区分度,因此会失去跨任务的泛化性能。
针对UIE缺失的泛化性能问题,USM进行了进一步的改进。因为UIE的Seq2Seq生成模型的黑盒特性,导致无法判断跨任务或跨模式的迁移是否成功,因此USM提出了统一语义匹配框架(Universal Information Extraction)。该框架将结构化和概念化转化为一系列有向Token-Linking操作,联合建模文本与模式,实现在不同结构和语义之间的共享抽取,从而实现了文本或文本pair的抽取。
这两个模型都达成了非常不错的性能,在任务上都超越了对应的小模型。但是他们都通用的使用一种提示来建模任务,缺少了任务之间的区分这失去了跨任务的泛化性。有没有可能让模型不需要微调,在不同任务上达到最优。甚至在没有见过的任务上也能效果较好呢。
因此在大模型出现之后,大家看到了大模型的通用性和泛化性在信息抽取领域的较大潜力。因此有一些探索性的工作尝试使用各种 prompting 的方法,将大模型运用于通用信息抽取任务上。这些工作展现出的较好的零样本能力,但是上下文学习的局限性,对于监督信息的低效利用,影响了模型性能的进一步激发,使得无法真正迈入实用化。
基于微调的生成式抽取方法
在这样的工作中,代表性的有 UIE( Universal Information Extraction)(Lu et al., 2022)。它的主要目标是通过预训练模型和特定的训练策略,以统一的方式处理各种不同的信息抽取任务。UIE 的核心之一是"Structural Schema Instructor",这是一个机制,将特定任务的 Schema 信息转化为生成过程的提示语。这些提示语在模型生成特定结构的文本时起到指导作用,帮助模型从原始文本中定位和抽取正确的信息。为了统一建模各类信息抽取任务,UIE 引入了一种名为“结构提取语言”(SEL)的工具,这种语言可以将不同的信息抽取任务编码为统一的表示。这样,不同的信息抽取任务就可以被统一建模为一个从文本到结构的生成过程。例如,无论是命名实体识别、关系抽取,还是事件抽取,都可以通过 SEL 编码为统一的结构,然后用相同的模型进行处理。这样的设计使得 UIE 在任务形式上具有了通用性,大大提高了信息抽取任务的处理效率和准确性。
![[Pasted image 20230529151808.png]](https://img.lzfluorite.xyz/2023/07/072f6086669b2fbbdab3f1fe5d03adfc.png)
UIE 与最先进的任务特定监督模型进行了比较如图。我们可以观察到:
- UIE 模型在几乎所有数据集和任务上都实现了最先进(SOTA)的性能,即使没有预训练(SEL)。
- 大规模预训练模型为通用 IE 提供了坚实的基础。与基线相比,预训练模型在大多数数据集中达到了最先进的性能,平均 F1提高了1.42%。
- 通过普遍建模 IE 任务和使用大规模数据集进行预训练,UIE 可以有效地捕获、共享和传输 IE 能力。预训练可以同时改进所有任务。
通用信息抽取(UIE)使用一个通用模型来解决多个信息抽取任务。然而,UIE 的 Seq2Seq 生成模型的黑盒特性导致很难判断跨任务或跨模式迁移的成功与否。为了克服这个问题,提出了统一语义匹配(USM)框架。
![[Pasted image 20230616145806.png]](https://img.lzfluorite.xyz/2023/07/c5c84f789153d9788ffcbd54567313fd.png)
USM 提供了一种统一的建模方法,可以为各种 IE 任务提供有效、健壮和可解释的解决方案。在 USM 中,从文本中提取具有未知标签的基本子结构是一个关键步骤。为了实现这一点,建立了三种基于有向 Token-Linking 的技术,用于实现结构化、概念化和配对概念化。 •Token-Token Linking for Structuring: 取所有有效的文本片段 •Label-Token Linking for Utterance Conceptualizing: 将有效的文本进行概念化 •Token-Label Linking for Pairing Conceptualizing: 建立文本与标签的链接 此外,USM的设计目的是解决异构监督数据问题,通过在上进行预训练,并利用来自IE任务的标注数据、通过对齐文本和知识库构建的远程监督数据以及机器阅读理解等NLP任务的间接监督数据。 •任务数据:来自信息抽取任务的标注数据,即数据样本都有一个金标准。 •远程监督数据:使用文本和知识库对齐构建的数据。 •间接监督数据:来自其他相关的 NLP 任务的数据,主要使用机器阅读理解的数据,将(问题-文档-答案)实例中问题作为结构,文档作为输入文本,答案作为标签。
USM框架达到了SOTA的效果,不使用预训练模型的情况下,Roberta初始化的USM框架也表现出了较好的效果,说明统一token-linking具有较强的可迁移性和泛化能力 ![[Pasted image 20230616150351.png]](https://img.lzfluorite.xyz/2023/07/966fc156d26193297073416927f76c6e.png)
异构数据的预训练的USM框架相比于Roberta初始化的USM框架在所有数据集上平均提高了0.74,说明异构预训练为信息抽取的结构化和概念化提供了更好的基础。
除了上述介绍之外还有一些生成式的方法如图: ![[Pasted image 20230616140809.png]](https://img.lzfluorite.xyz/2023/07/6ecaec0cdb4d4eb152da7ff5cbd3518a.png)
基于上下文学习的生成式信息抽取方法
大模型在信息抽取领域的可行性已经得到了部分实践的验证,但也存在一定的挑战和局限性。在生成式范式方面,大模型具有潜在的优势,这在小模型中已经相当成熟,例如 UIE 在传统任务上已经展现了良好的性能。然而,相较于 UIE 这种微调的生成模型,大模型的应用还有较大的限制,特别是在无法充分利用大量监督信息的情况下。因此,虽然大模型在生成式信息抽取中具有潜在的可行性,但仍需要面临小模型优异性能表现的挑战。
《Code4Struct: Code Generation for Few-Shot Structured Prediction from Natural Language》(Wang et al., 2022)这篇研究是大模型在信息抽取领域的一次实践尝试,它主要关注事件抽取(EAE)任务,通过将事件类型和约束映射为代码,并通过大模型CodeX和上下文学习进行代码生成以达到信息抽取。在50-shot任务设置下,其F1分数比现有最优模型高出20.8%,优于0-shot现有最优模型的F1分数12%。这篇研究展示了大模型在生成能力方面的强大潜力,以及这种能力在信息抽取领域的应用可能性。然而,该研究仅关注事件抽取任务,任务类型和标签类型较为有限。

Code4Struct 左,Think Again 右
代码生成模型在处理长距离信息建模方面具有潜力。这是因为代码生成通常需要理解和处理复杂的语义结构和长距离的语义关系,这在某种程度上加强了模型的长距离信息建模能力。此外,代码生成模型通常会产生一些明确的结构化输出,这有助于模型更好地处理和理解长距离和复杂的信息关系。
代码生成模型可以提高模型的指令理解能力。在代码生成过程中,模型需要理解并执行一些具体的编程指令,这在一定程度上提高了模型的指令理解和执行能力。
代码生成模型可以帮助模型更好地提取结构化信息。代码生成模型通常会产生一些结构化的输出,这可以帮助模型更好地理解和提取文本中的结构化信息。生成的可执行的代码,从而使信息抽取更加自动化和可扩展。
CodeIE: Large Code Generation Models are Better Few-Shot Information Extractors (Li et al., 2023),这项工作利用大型的代码生成模型(Code-LLM),例如 Codex,以解决命名实体识别和关系提取等信息抽取任务。与传统的基于自然语言生成的大型语言模型(NL-LLM)相比,此方法提出用代码而非自然语言来重塑结构化输出。作者通过设计代码风格提示,并将信息抽取任务设定为代码生成任务,展示了 Code-LLM 能够更好地对齐这些信息抽取任务。在七个基准测试的实验中,这种方法一直优于专门针对信息抽取任务(例如 UIE)设计的微调中等大小的预训练模型,并且在少样本设置中优于 NL-LLM。这项工作不仅提供了一个新的视角和方法来处理信息抽取任务,也为代码生成模型在其他 NLP 任务中的应用提供了新的可能性。
![[Pasted image 20230529211611.png]](https://img.lzfluorite.xyz/2023/07/333bad39d8f5aac5b7b11ecf9cd55638.png)
我们可以使用广泛的实验证明了代码生成模型进行信息抽取的性能,并通过一些实例来说明代码生成模型在信息抽取方面的优势。我们将探讨如何训练代码生成模型来自动提取名称实体、关系实体、事件实体等信息,并生成相关的代码。我们也可以探讨了如何设计合适的适用于信息抽取领域的生成方法并进行了广泛的实验。我们还将讨论如何使用这些生成的代码来进行调用工具和知识,并与传统的信息抽取方法进行比较。相信通过直接生成结构化生成的方式,知识工程领域会有较大的转变。
而另一篇题为《Thinking about GPT-3 In-Context Learning for Biomedical IE? Think Again》(Gutiérrez et al., 2022)的研究则提出了不同的观点。研究结果显示,与简单微调较小的预训练语言模型(PLM)相比,GPT-3的表现还有显著的差距。此外,尽管有更多的训练数据可供使用,GPT-3的上下文学习仍然只能带来较小的准确性提升。特别是在空类样本上,例如不包含命名实体的句子(对于命名实体识别 NER)或不包含任何目标关系的实体对(对于关系抽取 RE),GPT-3的上下文学习表现出频繁的错误。这些结果表明,虽然大模型在信息抽取领域有其潜力和价值,但其在实际应用中还需要进一步的优化和调整。
![[Pasted image 20230529161957.png]](https://img.lzfluorite.xyz/2023/07/a21e9f0e8160ff7063d581ac6988bd64.png)
这篇研究《Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples!》(Ma et al., 2022)对大模型在信息抽取领域的性能进行了全面的评估。实验结果发现,仅当标签注释数量有限时,大语言模型(LLM)才能优于小语言模型(SLM),即当标签类型及其每个样本都非常稀缺时。然而,一旦增加样本数量(如数百个),SLM 的性能将远超 LLM。这种现象可能由ICL的自然局限性引起,主要体现在两个方面。首先,由于ICL的最大输入长度限制,只有一小部分可用样本可以作为示例用于提示LLM。更进一步,即使在演示中增加更多的示例,也可能无法带来额外的性能提升。其次,随着模式(或标签类型的数量)的增加,提示中每个标签的样本数量会相应减少,因此很难通过指令很好地理解数十种(甚至数百种)标签类型及其语义交互。LLM 并不是一个好的小样本信息提取器。相比之下,即使与最优的基于 LLM 的方法相比,SLM 的表现大多数情况下都具有显著优势。例如,对于大多数命名实体识别(NER)和关系抽取(RE)数据集,最优的基于 LLM 的方法通常只能展现出与 SLM 相比也只有不显著的优势。
总而言之,ICL 方法具有巨大的潜力,然而理解 ICL 的能力是随着模型本身的基础能力而定的,模型能否良好地遵循指令的能力是在预训练阶段中注入的。而在具体的下游领域中,我们只能去寻找更好的方式设计 prompt 和 demonstration,更好的激发模型的能力,探究其在特定领域上的上限。在具体的细分领域,大模型并不适合通过少量的提示进行具有丰富的监督数据的任务,但是其泛化性和通用型仍然具有很强的应用价值,比如于开放式的信息抽取或者低资源的信息抽取。如果需要提升大模型的能力至能与小模型相媲美,那我们得继续寻找其他方法:如工具增强的语言模型、高效微调的语言模型等等。
前沿趋势分析
前述文章讲述了使用生成式方法统一建模信息抽取任务,从而解决传统方法数据稀缺、模型数量爆炸的痛点。事实上,UIE 从 ACL2022 至 2023 年都是非常具有影响力和高性能的工作。但是随着大模型展现出非常强大的性能,前沿研究主要开始关注如何将大模型利用到领域中的细分任务上,具体可以分为:使用指令微调增强大模型在信息抽取领域各个任务上的适配能力,使用工具增强方法调度抽取模型来完成复杂的抽取任务。
指令微调是将指令形式的任务描述转化为多个任务组成的指令集,并通过监督微调的方式让模型学习完成不同的指令任务的一种微调方法。在通用信息抽取领域,指令微调被引入到了 UIE 中。相比于参数微调,在结构和任务形式与预训练模型不统一的情况下,指令微调能够更好地适应多种任务。提示学习虽然能够让模型通过生成的方式完成各类任务,但无法改变模型参数在某些任务上性能不足的问题。
为了解决这个问题,InstructUIE(Gui et al., 2023) 将任务转化为指令的形式,也就是任务的描述,然后用多个任务构成的指令集进行微调。指令微调后,模型能够在遇见未知任务时,组合之前学习到的任务知识,完成任务。IE INSTRUCTIONS 数据集是这篇论文整理出来的,包含了3种任务和32个公开数据集,覆盖了多个领域,如科学、健康、社交、交通、新闻和百科等。IE INSTRUCTIONS 数据集将 IE 任务重建为 Seq2Seq 形式,每个任务实例都格式化为四个属性:任务指令、选项、文本和输出,并设计了辅助任务为任务提供补充的信息,如对于关系抽取任务,引入实体对抽取和关系分类等。结果显示,指令微调提高了模型在下游任务中的适配性,在不需要微调的实验设置下,达成了超越 SOTA 的性能。CAMA(Wang et al., 2023) 使用了更大的语言模型和更丰富的指令集进行微调,在特定的任务上泛化超越了 ChatGPT 的性能。我相信,在未来,在任务领域内微调一个较小的大模型,提升具体的任务的泛化性和实用性是很有应用前景的方向。
知识图谱的数据需要更新,语言模型的信息也需要时时更新,然而网络信息无穷无尽,这时候使用参数微调的方式更新模型就较为低效。因此我认为在前沿趋势方向,基于工具增强的大模型有很大的发展潜力。大模型可以通过使用工具调度、构建知识图谱,实时更新知识,搜索网络获取相关信息作出决策,真正意义上的结合了知识的流动性和不变性。在这个方向我介绍了基于工具增强的一些工作,当然除工具增强外,如何让模型持续的学习新知识也是重要的研究点。
基于指令微调的生成式抽取方法
小模型,我们可以定义为参数数量通常在60B 以下的模型。它们的主要优点是较低的训练和微调成本,这使得它们在资源有限的环境中更加实用。小模型在特定任务上的性能通常非常优秀,这反映了它们的专用能力。但是,小模型的通用能力往往较弱,尤其是当面对复杂或未见过的任务时。
相比之下,大模型的参数数量通常在60B 以上。它们的训练和微调成本极高,这主要是因为大模型需要消耗大量的计算资源。因此,大模型通常只能通过 API 进行调用。然而,大模型的通用能力强,这使得它们能够处理各种各样的任务,甚至有时会显示出涌现能力,即模型在未经特定任务训练的情况下,仍能表现出对该任务的理解和处理能力 (Wei et al., 2022)。
大模型的强大能力在很大程度上源于上下文学习和指令微调的结合。在2022年,谷歌引领时代潮流,提出了指令微调的概念。这一创新性的想法推动了后续诸如 Instruct GPT (Ouyang et al., 2022)等我们熟知的强大模型的诞生。传统的微调方式往往需要为不同任务生成多个模型,资源消耗大。然而可以灵活适配各个任务的 prompt 方法无法充分发挥大模型的特定性能。而指令微调,它将多种任务转化为指令的形式,使得大模型能够同时适配并最优化多个任务的性能,使模型获得了泛化到尚未存在任务的能力 (Ouyang et al., 2023)。我们观察到,随着模型参数的增加,大模型的各种任务能力发生了指数型的跃迁,性能的提升趋势明显。
![[Pasted image 20230529155222.png]](https://img.lzfluorite.xyz/2023/07/c54f5e194effb26d9c0ad2b963bd8c83.png)
然而,真正让大模型的能力得以淋漓尽致的展现,是一种名为思维链的新技术。思维链是指在给模型演示指令时加入模型的思考过程。这样,模型在生成答案时也能模仿这种思考过程进行一定的"推理",从而极大地提升其正确率。通过上下文学习和思维链的结合,大模型的推理能力被进一步激发。我们注意到,当模型的参数规模较小时,这种提升并不显著。然而,随着参数规模的增大,提升变得越来越明显。这从根本上证实了一种观点:某些能力可能并不存在于小模型中,而是需要在大模型中才能真正显现出来 (Wang et al., 2022)。
![[Pasted image 20230529155339.png]](https://img.lzfluorite.xyz/2023/07/451a0765cbc2984e3ee91bfef8896c71.png)
知识图谱是图化的、高效的知识表示,也可以看作符号化表示的知识,具有直观性、简易性、可解释性。在我看来,知识图谱从直观的需求角度不可被替代,对于下游研究也有较大意义。大型模型通常具有很好的通用性,这使它们能够处理各种各样的任务。这也使得大型模型在构建知识图谱时,可以适应各种不同的输入和输出格式。其次,大型模型能够理解和处理大量的数据,这使它们在构建大规模知识图谱时具有优势。它们可以处理各种复杂的关系和实体,从而建立一个全面和详细的知识图谱。最后,大模型本身具有丰富的世界知识,可以在构建知识图谱的同时对图谱进行一定的补全和修正。因此,研究如何通过大模型自适应地构建图谱具有较大的实用价值。
通过大模型构建知识图谱主要可以关注两个方向:高效微调塑造知识图谱生成的领域大模型、大模型通过知识图谱辅助进行增强。
低参数微调的主要优势是,它可以在训练过程中减少计算负载,缩短训练时间,并提高模型的灵活性。微调也让模型更适应特定的任务和数据集。然而,对于大型语言模型,特别是像 GPT-3.5-turbo 这样的模型,它们的性能通常低于最新的研究。这是因为这些模型通常更大,更复杂,训练和微调需要更多的时间和计算资源。高效微调就使得大模型能够以相对较低的成本,像特定的领域进行转化。另一方面,上下文学习的劣势在于它通常对输入的顺序和上下文极为敏感,这可能导致模型对输入的微小变化过于敏感。与此同时,上下文学习难以让模型学习到复杂的行为模式和监督信息,对于具有丰富监督信息的领域存在资源浪费。
将高效微调和大模型结合,我们能够构造具有插拔能力、适配能力的大模型。在信息抽取领域,一直有很多研究者在关注这个方向,如"InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction"(Gui et al., 2023) 和 "InstructIE: A Chinese Instruction-based Information Extraction Dataset"(Wang et al., 2023)。"InstructUIE" 提出了一个基于指令调整的统一信息提取框架。该研究利用了大型语言模型的优势,通过微调来改进信息提取任务的性能。这篇文章对大型语言模型在信息提取任务上的应用提供了新的视角,展示了微调的价值。而 "InstructIE" 则介绍了一个新的信息提取任务——基于指令的IE。这篇文章构建了一个新的数据集,并对不同的基线模型进行了评估。这项研究强调了基于指令的IE任务的挑战,同时也展示了大型语言模型在解决复杂问题上的潜力。
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction ![[Pasted image 20230529164309.png]](https://img.lzfluorite.xyz/2023/07/05b07431f559f3d2175d0f8cb4b28d21.png)
![[Pasted image 20230619164710.png]](https://img.lzfluorite.xyz/2023/07/e80f0eda2a4eeb1c016a6a24891d4556.png)
指令微调能够提高模型在下游任务中的适配性,让模型能够更好地完成各类不同的任务。因此,在实验设置中不需要进行微调,InstructUIE就能够达到超过SOTA的性能水平,这表明指令微调相比前文的工作,在更复杂的任务上实现了大幅提升。事实上,指令微调能够有效地激发模型的难样本能力,也就是模型在面对更具挑战性的任务时的表现能力,进一步提高模型性能。
微调大型语言模型在信息抽取上的性能有显著提升,这主要归功于微调过程使模型更加适应特定任务和数据集的能力。对于 CAMA (Wang et al., 2023)模型,首先利用大规模中文语料库进行预训练,增强了模型对中文理解的能力和知识储备;然后利用指令数据集对模型进行微调,提高了模型对人类指令的理解。这种预训练与微调的组合使模型在信息抽取任务上的性能有了显著提升,这在 CaMA-13B-LoRA 模型上得到了明显的体现。
![[Pasted image 20230529213514.png]](https://img.lzfluorite.xyz/2023/07/2d59b00c7cc01cac8837d4bd99c8ffb7.png)
此外,Alpaca 模型的表现也进一步证实了微调大型语言模型的优势。Alpaca-7B 模型在包含52K 指令的数据集上进行微调,提升了其理解和遵守指令的能力,尽管其模型大小与 LLaMA7B 相同,却在 InstructIE 任务上展现了出色的性能。而更大的 Alpaca-13B 模型,其性能也进一步提高,说明增加模型尺寸能够进一步提升整体性能。Alpaca-13B 经过微调后与 ChatGPT ICL 的性能持平,说明在特定领域上,我们其实不需要通用的大模型,仅仅用小模型进行微调也能取得不错的效果。
![[Pasted image 20230529214330.png]](https://img.lzfluorite.xyz/2023/07/96afa8cb4b4cfcde37170cdd6dea602b.png)
微调与 LoRA(局部重排)的比较也揭示了有趣的现象。MT5模型经过微调后的结果与在大得多的模型上执行 LoRA 的结果相当。这说明 LoRA 的策略,即有选择性地修改模型参数的一小部分,相对于调整所有参数的微调策略,可能效率较低。
未来,大型语言模型在信息抽取上的应用前景广阔。首先,通过增加模型大小,进一步预训练和微调,我们可能获得更高的性能。其次,探索新的微调策略,比如局部重排(LoRA),也是一个有前景的研究方向。此外,我们也可以尝试构建更丰富、更具挑战性的数据集,以此来训练和微调模型,挖掘模型的潜力。最后,如何更好地平衡预训练和微调,以获得更优的模型性能,也是值得深入研究的问题。
工具增强的大型语言模型
工具学习是一种新兴的研究领域,其主要目标是利用模型来管理工具,并代替人类进行序列决策。工具学习利用基础模型的丰富世界知识和推理能力进行复杂的推理和规划。工具学习的产生主要是基于大型基础模型的发展。这些基础模型,如 GPT-3等,通过大规模的数据预训练,获得了丰富的世界知识和推理能力。这使得它们能够理解人类的指令,并进行复杂的推理和规划,从而实现工具学习。
![[Pasted image 20230530111904.png]](https://img.lzfluorite.xyz/2023/07/fdcbfd8eb8c4436d2c22d1bd92680288.png)
Qin, Yujia, et al. "Tool Learning with Foundation Models." arXiv preprint arXiv: 2304.08354 (2023).
大型模型之所以能进行工具学习,主要有以下几个原因:
从大模型的能力而言:
- 大型模型具有丰富的世界知识:通过大规模的数据预训练,大型模型学习到了大量的事实知识、语言知识和常识知识。这使得它们能够理解各种类型的工具,并知道如何使用这些工具。
- 大型模型具有强大的推理能力:大型模型不仅能够理解工具,还能够进行复杂的推理和规划。这使得它们能够根据给定的任务,选择合适的工具,并制定出有效的解决方案。
- 大型模型能够理解人类的指令:大型模型能够理解人类的自然语言指令,并根据这些指令进行操作。这使得它们能够根据人类的需求,选择和使用合适的工具。 从工具能增强大模型的方面而言:
- 改进大模型的时效性和生成幻觉问题:通过工具学习,模型可以利用各种工具(如搜索引擎)来获取实时信息,从而提高其时效性。也可以根据外部工具纠正自身的结果并获得反馈。
- 提高模型的性能和实践外延:通过工具学习,模型可以更好地解决各种任务。例如,模型可以利用搜索引擎来获取实时信息,或者利用计算器来进行复杂的计算。甚至拓展到实践外延、具身学习,机器可以从自然环境中的互动进行学习,更够帮助他们更好的对概念进行理解。
目前,工具学习的整体框架如图 (Qin et al., 2023):
![[Pasted image 20230530171009.png|500]](https://img.lzfluorite.xyz/2023/07/f7aa28868a36124a032fe74712ebd9cc.png)
- 工具集(Tool Set):这是一组具有不同功能的工具。这些工具可以是各种各样的,包括但不限于语言模型、知识图谱、数据库等。
- 环境(Environment):环境提供了工具操作的平台。这可以是一个物理环境,也可以是一个虚拟环境。环境的作用是为工具提供输入,以及接收工具的输出。
- 控制器(Controller):控制器的作用是提供可行的计划来满足用户的请求。这包括选择合适的工具,以及决定如何使用这些工具。
- 感知器(Perceiver):感知器的作用是将反馈总结给控制器。这可以帮助控制器了解工具的效果,以及如何改进工具的使用。
转化为公式: 控制器 生成计划 ,整体任务被建模为在历史记录、指令和反馈下生成行为的概率
这可以被建模为两个子任务
- 理解指令并选择合适的工具
- 根据工具性质和环境决定合适的行为
PAL (Gao et al., 2023)是比较早期但是非常具有代表性的工作。做的非常详细优雅,很直观地展现出大模型使用工具在具体任务上的直观改进。这篇论文介绍了一种名为 ProgramAided Language models (PAL)的新方法,该方法使用大型语言模型(LLM)阅读自然语言问题并生成程序作为中间推理步骤,但将解决步骤卸载到运行时,如 Python 解释器。使用 Python 解释器进行推理,可以在所有这些自然语言推理任务中获得更准确的结果,比使用更大模型的结果更好。例如,使用 CODEX 的 PAL 在 GSM8K 数学词问题基准测试中实现了 fewshot 的最高准确度,超过了使用链式思维的 PaLM-540B 的15%。这项工作的意义在于,它展示了神经网络 LLM 和符号解释器之间的协同作用,这种协同作用可以提高模型在数学、符号和算法推理任务中的性能。
从更长远的角度来看,目前针对于人类设计的工具,针对于程序调度设计的工具不一定适合大型语言模型。大型语言模型应该有适应其使用方式进行设计的,或者其自己创造的工具。CREATOR: Disentangling Abstract and Concrete Reasonings of Large Language Models through Tool Creation (Qian at el. , 2023)这篇论文提出了一种名为 CREATOR 的新框架,该框架通过文档和代码实现,使大型语言模型(LLM)能够创建自己的工具。CREATOR 将 LLM 的能力分解为两个不同的阶段:抽象工具创建和具体决策执行。有意思的是,即使不使用工具,创建工具的过程似乎增强了语言模型的理解能力,这也导致了 LLM 性能的提高。
引用
Wei, X., Cui, X., Cheng, N., Wang, X., Zhang, X., Huang, S., Xie, P., Xu, J., Chen, Y., Zhang, M., Jiang, Y., & Han, W. (2023). Zero-Shot Information Extraction via Chatting with ChatGPT (arXiv: 2302.10205). Wang, X., Zhou, W., Zu, C., Xia, H., Chen, T., Zhang, Y., Zheng, R., Ye, J., Zhang, Q., Gui, T., Kang, J., Yang, J., Li, S., & Du, C. (2023). InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction (arXiv:2304.08085). Gui, H., Zhang, J., Ye, H., & Zhang, N. (2023). InstructIE: A Chinese Instruction-based Information Extraction Dataset (arXiv:2305.11527). Sun, T. X., Liu, X. Y., Qiu, X. P., & Huang, X. J. (2022, May 28). Paradigm Shift in Natural Language Processing. Machine Intelligence Research, 19(3), 169–183. Lu, Y., Liu, Q., Dai, D., Xiao, X., Lin, H., Han, X., Sun, L., & Wu, H. (2022). Unified Structure Generation for Universal Information Extraction. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Lu, Y., Lin, H., Xu, J., Han, X., Tang, J., Li, A., Sun, L., Liao, M., & Chen, S. (2021). TEXT2EVENT: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Wei, Z., Zhao, Y., Lu, K., Zhou, G., Xu, J., & Yan, J. (2022). Finetune Language Models are Zero-Shot Learners. ICLR. Ouyang, X., Li, M., Liu, S., Li, P., Tang, J., & Zhou, G. (2023). Training Language Models to Follow Instructions with Human Feedback. arXiv preprint arXiv:2203.02155. Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2021). Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey. arXiv preprint arXiv: 2111.01243. Wang, X., Li, S., & Ji, H. (2022). Code4Struct: Code Generation for Few-Shot Structured Prediction from Natural Language. arXiv preprint arXiv:2210.12810. Gutiérrez, B. J., McNeal, N., Washington, C., Chen, Y., Li, L., Sun, H., & Su, Y. (2022). Thinking about GPT-3 In-Context Learning for Biomedical IE? Think Again (arXiv: 2203.08410) Ma, Y., Cao, Y., Hong, Y., & Sun, A. (2023). Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples!. arXiv preprint arXiv:2303.08559. Qian, C., Han, C., Fung, Y. R., Qin, Y., Liu, Z., & Ji, H. (2023). CREATOR: Disentangling Abstract and Concrete Reasonings of Large Language Models through Tool Creation. arXiv preprint arXiv: 2305.14318. Liu, X., Ji, K., Fu, Y., Tam, W. L., Du, Z., Yang, Z., & Tang, J. (2021). P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks. arXiv preprint arXiv:2110.07602. Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv: 2106.09685. Qin, Y., Hu, S., Lin, Y., Chen, W., Ding, N., Cui, G., Zeng, Z., Huang, Y., Xiao, C., Han, C., Fung, Y. R., Su, Y., Wang, H., Qian, C., Tian, R., Zhu, K., Liang, S., Shen, X., Xu, B., … Sun, M. (2023). Tool Learning with Foundation Models (arXiv:2304.08354). Wang, Y., Zhou, J., & Zhang, W. (2023). InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction. arXiv preprint arXiv: 2304.08085. Gao, L., Madaan, A., Zhou, S., Alon, U., Liu, P., Yang, Y., Callan, J., & Neubig, G. (2023). PAL: Program-aided Language Models (arXiv: 2211.10435). Hernandez, E., Li, B. Z., & Andreas, J. (2023). Measuring and Manipulating Knowledge Representations in Language Models (arXiv:2304.00740). Hu, H., Lu, H., Zhang, H., Lam, W., & Zhang, Y. (2023). Chain-of-Symbol Prompting Elicits Planning in Large Langauge Models (arXiv:2305.10276). Li, P., Sun, T., Tang, Q., Yan, H., Wu, Y., Huang, X., & Qiu, X. (2023). CodeIE: Large Code Generation Models are Better Few-Shot Information Extractors (arXiv:2305.05711). Ma, Y., Cao, Y., Hong, Y., & Sun, A. (2023). Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples! (arXiv: 2303.08559). Chen, Y. (2023). Paradigm transfer in knowledge graph construction: From generative IE to LLM as knowledge base (Report). Chen, Y. (2023). Adaptive knowledge graph construction based on large-scale model fine-tuning (Report). Chen, Y. (2023). Information extraction applications in large language model scenarios (Report). Chen, Y. (2022). End-to-end structured information extraction based on generative models (Report).
- 基础任务介绍
- 典型工作介绍
- 基于微调的生成式抽取方法
- 基于上下文学习的生成式信息抽取方法
- 前沿趋势分析
- 基于指令微调的生成式抽取方法
- 工具增强的大型语言模型
- 引用